前沿 | 谷歌最新AR/VR专利提出单个RGBD摄像头进行体三维捕捉
复杂的捕获设备可用于生成非常高质量的人类体三维重建。这种系统主要依靠昂贵的高端基础设施来处理捕获的大量数据。由于每帧需要数分钟的计算时间,所以当前的技术不适合实时应用。
另一种进行人类体三维重建的方法是将实时非刚性融合管道扩展到多视图捕获设置中。然而,相关的结果存在几何失真、纹理质量差和光照不准确等问题,难以达到增强现实/虚拟现实应用所要求的质量水平。
针对这个问题,谷歌正在积极探索可行的实时解决方案。
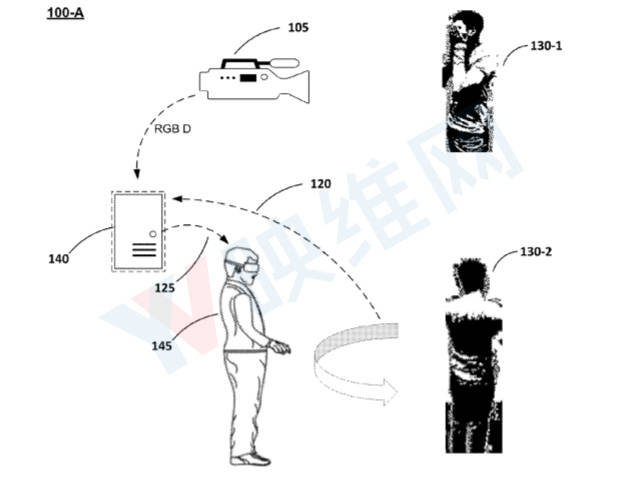
美国专利商标局日前公布了一份名为“Volumetric Capture Of Objects With A Single Rgbd Camera”的专利申请。其中,谷歌描述了一种利用单个RGBD摄像头对对象进行体三维捕捉的方法和系统。
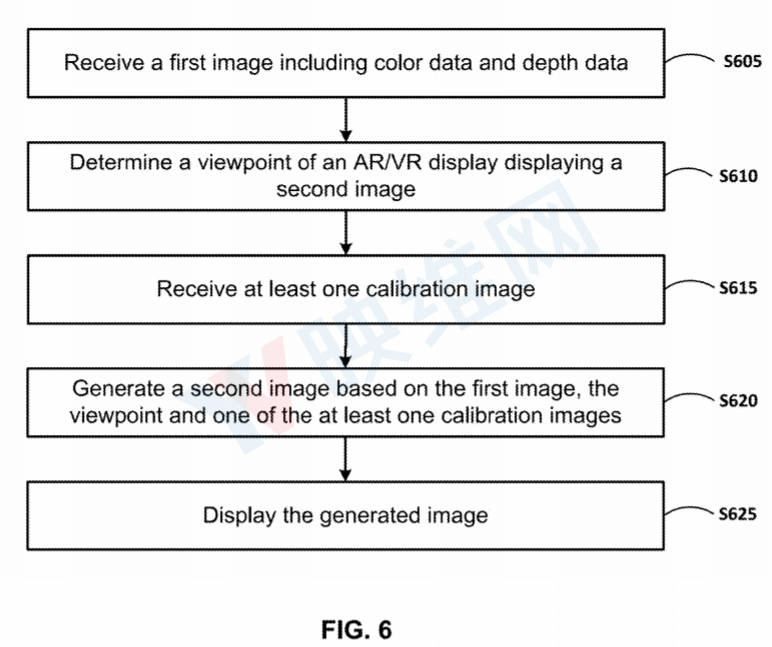
在一个实施例中,一种方法包括使用单个RGBD摄像头接收包括颜色数据和深度数据的第一图像;确定与显示第二图像的增强现实和/或虚拟现实显示器相关联的视点;接收包括第一图像中的对象的至少一个校准图像;并且根据所述第一图像、所述视点和所述至少一个校准图像生成第二图像。
在一个实施例中,所述的至少一个校准图像可以是对象的轮廓图像。第二图像的生成可以包括,通过将二维关键点映射到与至少一个校准图像相关联的深度数据的相应三维点,确定对象的目标姿态。第二图形的生成同时可以包括,使用卷积神经网络将所述至少一个校准图像和所述对象的目标姿态作为输入,通过在所述至少一个校准图像中翘曲所述对象来生成所述第二图像。
进一步而言,第二图像的生成可以包括,在具有至少一个校准图像作为输入的卷积神经网络的第一通道中生成至少一个部分掩模(Part Mask),在卷积神经网络的第一通道中生成至少一个部分图像(Part-Image)。然后,卷积神经网络将至少一个部分掩模和至少一个部分图像作为输入,并在第二通道中生成第二图像。第二图像的生成可以包括使用卷积神经网络的两个通道,所述卷积神经网络通过最小化与对象翘曲相关的至少两个损失来训练。可以使用神经网络混合第二图像以生成第二图像的缺失部分。第二图像可以是对象的轮廓图像。所述方法同时包括将第二图像与背景图像合并。
在一个实施例中,所述方法同时可以包括预处理阶段。在预处理阶段中,可以在对象姿态改变的同时捕获多个图像;将所述多个图像存储为至少一个校准图像;根据目标姿态为所述至少一个校准图像中的每一个生成相似性得分;以及根据相似度得分从所述至少一个校准图像中选择所述至少一个校准图像。
简单来说,系统可以首先通过RGBD摄像头捕获包含颜色数据和深度数据的第一图像并确定第一图像中的对象的姿态;系统可以同时根据眼动追踪确定用户的视点;根据对象姿态和用户视点,系统可以确定校准图像;最后,根据第一图像、用户视点和校准图像,系统利用卷积神经网络实时生成在AR/VR显示器显示的第二图像。其中,第二图像为体三维多视图图像。
谷歌在专利中写道:“通过利用卷积神经网络,单个RGBD摄像头可以实时地捕获和储存校准图像,并用于为增强现实和虚拟现实生成高质量的体三维重建多视图图像。”