前沿 | 田纳西大学研发首款单耳生物传感器,无需照相机也能检测用户表情
“通过面部和眼部微小运动,即可操控周边电子设备;无需摄像头,戴着 VR 头盔就能实时捕捉面部表情、追踪面部动态及眼部动态;即便佩戴着口罩,也能让别人看到你的嘴部活动。” 这是由美国田纳西大学刘健教授团队、联合德州大学阿灵顿分校 VP Nguyen 教授团队联合研发的耳戴式设备 BioFace-3D。
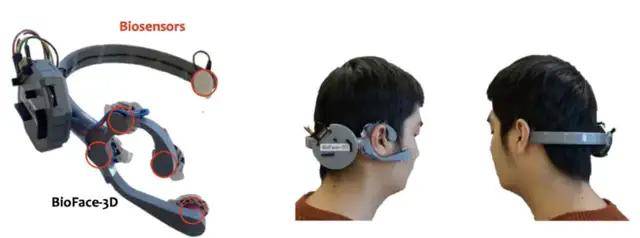 图 | BioFace-3D 耳戴式设备(来源:MobiCom 2021)
图 | BioFace-3D 耳戴式设备(来源:MobiCom 2021)
日前,该团队设计出一款全新耳戴式设备,可持续收集用户生物信息,并可对其面部活动进行 3D 准确还原[1]。据其介绍,这是第一款基于生物信号、并能准确、持续、无侵入式地进行面部追踪和还原的耳戴式设备。
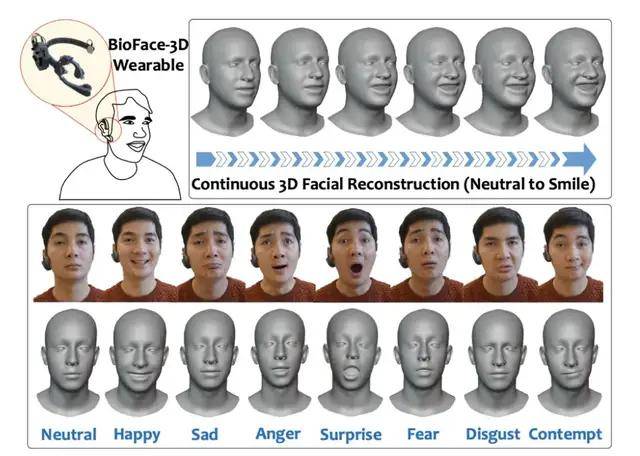 图 | 基于耳戴式设备的多种表情面部还原(来源:MobiCom 2021)
图 | 基于耳戴式设备的多种表情面部还原(来源:MobiCom 2021)
日前,相关论文以《BioFace-3D:通过轻型单耳生物传感器连续进行三维面部重建》(BioFace-3D: Continuous 3D FacialReconstruction Through Lightweight Single-ear Biosensors)为题,发表在计算机网络及移动计算领域国际顶级会议 ACM MobiCom2021 上,美国田纳西大学刘健教授课题组 MoSIS Lab 博士生武艺担任第一作者。
 图 | 相关论文(来源:MobiCom 2021)
图 | 相关论文(来源:MobiCom 2021)
他认为,基于摄像头的传统面部追踪系统存在许多限制,进而会带来诸多不便:“摄像头是获取面部信息时最直观的使用方法。但是,必须保证光照充足,脸部也要时刻对准镜头,并且镜头必须没有遮挡。
 图 | 武艺(来源:武艺)
图 | 武艺(来源:武艺)
此外,摄像头的高功耗和隐私安全也亟待解决,这导致摄像头在某些场景很难投入使用,比如漆黑环境中、人物戴着口罩时、以及体验 VR 游戏需要进行大量身体活动时。”
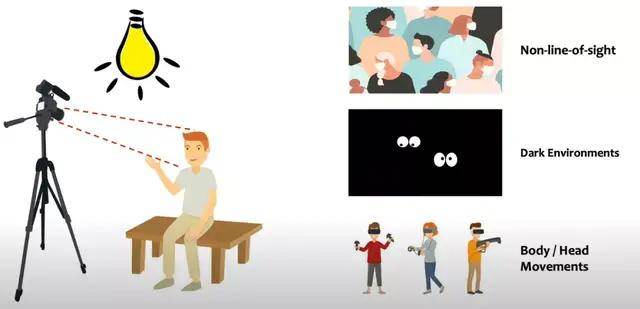 图 | 基于摄像头的面部动态捕捉系统的诸多限制(来源:MoSIS Lab@UTK)
图 | 基于摄像头的面部动态捕捉系统的诸多限制(来源:MoSIS Lab@UTK)
基于此,该团队设计出首款可摆脱这些限制、并能持续进行面部追踪还原的耳戴式设备。耳机中包含一个接地电极插槽,并与环绕在脑后的头带集成。针对不同的头型,他们设计了大中小三种尺寸的原型。
头带中还包含一个电路盒,用来储存各种硬件。耳戴式设备的所有组件均由 PLA (聚乳酸)的 3D 打印技术制造而成,因此机身重量较轻。BioFace-3D 主要基于德州仪器 ADS1299 芯片的生物放大器电路、OpenBCI 公司的 Cyton Board、以及粘在用户皮肤上的氯化银电极表面电极,上面还集成了蓝牙模块。
其原理是,当脸部做活动时,肌肉会进行收缩从而产生微弱的电信号,在医学上这叫肌电图(EMG)。该耳戴式设备上的生物传感器,在捕捉到这些电信号并经过放大器放大后,可通过蓝牙将信号发给计算机。接着,计算机上的深度学习算法即可开始工作,持续不断地将未经处理的生物信号、以每秒 20 帧的速度转换为 53 个表现面部特征的特征点。
不同面部动作,会牵扯到不同肌肉组织,从而产生不同的肌电图。而深度学习算法可精确捕捉到这些差别,借此还原出使用者的面部表情。在经过卡尔曼滤波的处理后,这些面部特征点经由一个事先训练好的头部模型,即可转化为 3D 的虚拟形象。
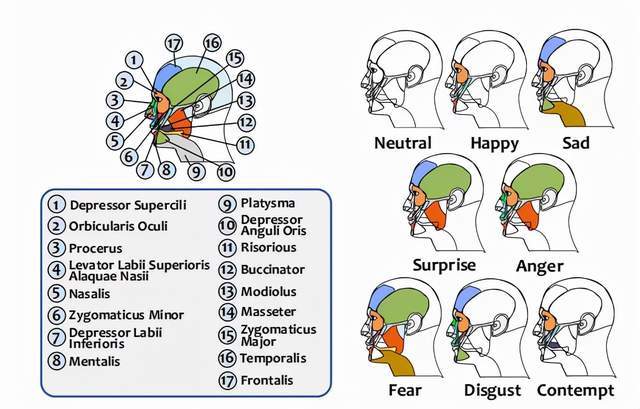 图 | 不同的面部动作对应不同的肌肉组织(来源:MobiCom 2021)
图 | 不同的面部动作对应不同的肌肉组织(来源:MobiCom 2021)
研究中,该团队召集 16 名志愿者,来参与测试该耳戴式设备。实验结果表明,在平均 1.85 毫米的绝对误差下,该设备可准确还原 53 个表现用户表情的面部特征点,这可与大多数最先进的基于摄像机的解决方案相媲美。
当用户戴上口罩,该系统仍能以 1.93 毫米的绝对误差对面部做以准确还原。在实验结束后,武艺还让志愿者填写体验问卷,结果显示有 13 名参与者对该设备持积极态度并愿意使用它。此外,该系统的功耗为 118 毫瓦,在一块锂电池的作用下可连续 8 小时采集并发送生物信号。
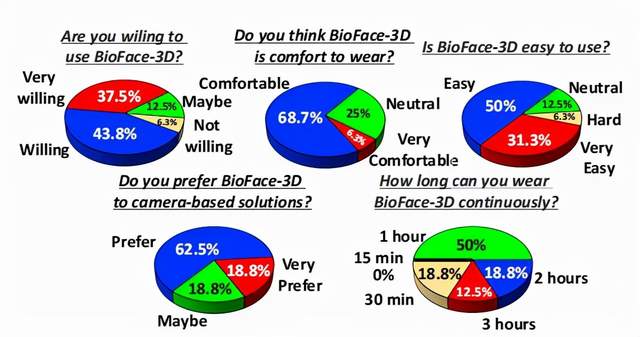 图 | 用户调查问卷的结果(来源:MobiCom 2021)
图 | 用户调查问卷的结果(来源:MobiCom 2021)
通过生物信号,可生成 53 个特征点的坐标
回忆研究流程,其表示第一步是获取高信噪比的生物信号,来保证用户面部信息可被有效捕捉到。同时为提高用户体验,不仅要保证生物传感器的数量尽可能地少,还要保证这些传感器可被设置在非敏感面部区域。
测试之后,该团队将 5 个生物传感器设置在佩戴者耳部附近,该区域可在不牺牲信噪比的同时提高使用体验。基于这五个生物传感器的位置,他们完成了耳戴式设备的设计和 3D 打印工作。
下一步是通过构建算法,来从未处理的生物信号中,准确地还原面部特征点。这时就得用到深度学习,它能通过算法找出不同信号之间的联系,从而达成人类无法做到的事情。
要想把模型训练成功,首先要收集大量生物信号、以及与之对应的面部特征点的真值。在采集生物信号的同时,武艺等人使用摄像头记录下用户面部活动,进而通过预先训练好的高精度视觉神经网络,来从视觉信号中获取面部特征点的真值。
经过反复测试,该系统最终选择了基于含有 98 个面部特征点的 WFLW 数据集训练的视觉模型,并从 98 个特征点中选择 53 个代表性特征点, 包含眉毛、眼睛、鼻子和嘴巴,并可展现出 8 种不同的面部表情,如无表情、高兴和生气等。这些提取出来的特征点坐标,将用来训练以生物信号为输入的神经网络。
在测试阶段,该系统不仅无需使用摄像头,而且仅凭生物信号即可生成 53 个特征点的坐标,即可达成和基于摄像头的方法相媲美的效果。
由于持续收集的生物信号,从本质上来说就是时间序列,为此该团队设计了基于一维卷积的神经网络,以此来将生物信号以每秒 20 帧的速度转换为 53 个特征点。武艺表示,从未处理的时间序列信号中,一维卷积神经网络可快速提取代表性特征,并进行高效准确的面部还原。
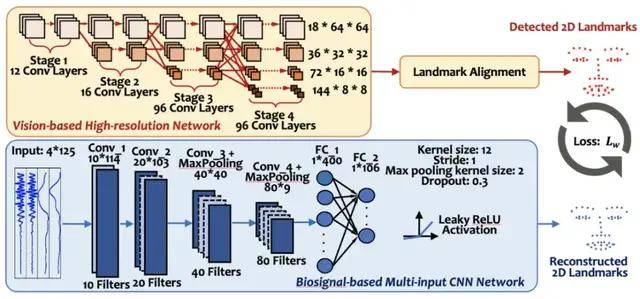 图| 从预先训好的视觉神经网络中提取真值,再通过以生物信号为输入的网络进行还原(来源:MobiCom 2021)
图| 从预先训好的视觉神经网络中提取真值,再通过以生物信号为输入的网络进行还原(来源:MobiCom 2021)
在一块英伟达 2080Ti 显卡的运作下,神经网络能以 0.033 毫秒一帧的速度,迅速生成面部特征点。为保证生成的 3D 脸部动画的稳定性,该系统对生成的面部特征点序列,进行了卡尔曼滤波,以提升 3D 动画的最终视觉效果,即视觉观感更顺滑。经过滤波后的特征点,会经过预先训练好的模型生成对应的虚拟形象。
可用于阿兹海默症的早期预警等
该设备可摆脱必须在用户面前放一台摄像头的限制,涉及的系统也能和诸多新兴技术进行有效结合。例如,该系统可作为 VR 头盔的扩展,就算你戴着 VR 头盔也可被实时获取面部表情。
把这些表情实时导入 VR 社交软件中,即可将表情还原出来,并能提升沉浸感,从而让虚拟世界更真实。
类似地,在疫情期间即使大家都戴口罩,该系统也可捕捉到人们的表情。也可作为人机交互的无声语音接口,让用户通过做表情就能给电子产品发出指令。
该设备也有用于健康监控的潜在能力,通过长期监测用户表情,即可评估其认知功能,进而可用于阿兹海默症的早期预警。
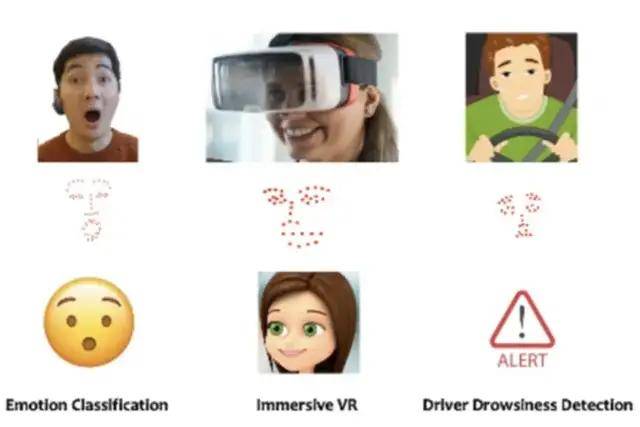 图 | 可能的应用市场(来源:MoSIS Lab@UTK)
图 | 可能的应用市场(来源:MoSIS Lab@UTK)
据悉,此次论文也是武艺博士期间以一作身份发表的首篇顶会论文。在提交论文的截稿日几天前,他经历了一个小插曲:字号用错了。MobiCom 要求 10 号字体及以上,而临到头他才发现一直使用 9 号字。如果没有发现及时,论文很有可能被拒稿,并导致团队努力付之东流。为此,武艺和团队连夜进行大幅删减、修改,赶在截稿日前一天完成全部论文写作。他说这个插曲给自己敲响了永生难忘的警钟。
武艺和该论文的另一位作者李倬航,目前均是田纳西大学 EECS 系的博士生, 在刘健教授课题组 MoSIS Lab 攻读博士学位。他俩从本科时便是同学,均毕业于电子科技大学,硕士则毕业于罗格斯大学计算机工程系。
未来,该项目团队计划将通过设计定制型数据收集板,来进一步提高系统的能源效率,也将使用更紧凑的模拟和更少的通道。团队还计划开发一个与主要 AR/VR 平台(如 OpenVR)兼容的 API 库和一款 App,以便去支持各种移动设备。